Reliability and Fatigue as Random Processes in Tabletop
There has been some discussion in the ether over the past month about the function and utility of randomness in adventure modules. This discussion probably goes back to the foundations of the hobby, but the most recent bout started with a post from Sam Sorenson on Editing your RPG Manuscript. His advice included a more judicious use of random tables, a hallmark of OSR and Post-OSR design. Gamers and designers have strong opinions about random tables, hence the ensuing discussion in the spaces that I frequent.
Nova of Idle Cartulary was inspired to throw her hat in the ring on the general concept of randomness, with a phenomenal post, asking What is randomisation for in modules? In turn, this initiated an impromptu bandwagon from Prismatic Wasteland calling for bloggers to discuss randomness, with a target date determined (appropriately) at random.
In my day job, the most randomness I usually deal with is whether my manager will answer my emails or not. My background is engineering mechanics, however, which puts me in contact with some honest-to-goodness random processes that tend not to show up in your average fantasy elfgame. I wanted to talk about two random processes that could be interesting to work into system and module design today: Reliability and Mechanical Fatigue.
Reliability
When engineers design and analyze systems, they look broadly at two sort of requirements. There are Functional Requirements, which are statements of what the system needs to do, and Quality Factors, which sort of draw the box around how well the system needs to do it. Quality Factors are also called "-ilities" because they include operability, sustainability, maintainability, availability, and the list goes on to meet the size of your budget. The most intuitive (and most mis-applied) quality factor is Reliability, which is the probability that your system will still be working after some amount of time has elapsed. Broadly, the more reliable your doodad is, the higher your reliability is (from 0% to 100%) and thus the more likely that it will still be working at the end of some period of time.
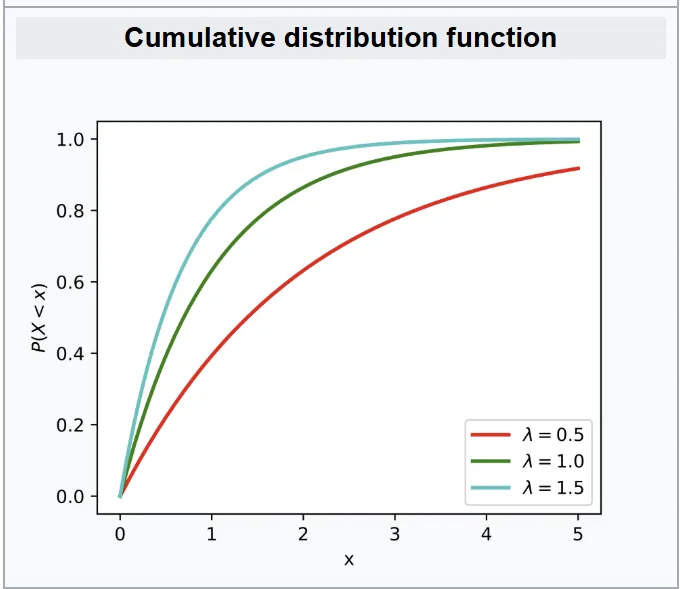 More on the Exponential distribution in a minute. Note that as the independent variable increases, the total probability approaches 1 (100%). This figure is showing the probability of failure, which is the inverse of reliability.
More on the Exponential distribution in a minute. Note that as the independent variable increases, the total probability approaches 1 (100%). This figure is showing the probability of failure, which is the inverse of reliability.
Reliability is tricky enough to model correctly that it is usually one person's full time job to just manage the mathematical models for a handful of systems. My company has a few hundred engineers and two full-time reliability analysts who try to turn our chicken scratch into customer confidence. The basic theory of it, however, is capturing the intrinsic failure rate of each of the piece-part components in a design and building a network of the components that properly communicates when an individual component failure leads to an overall system failure. Here, a system failure usually means that you are no longer meeting your Functional Requirements. Thus, we see how Quality Factors map to how well and/or how long you meet Functional Requirements.
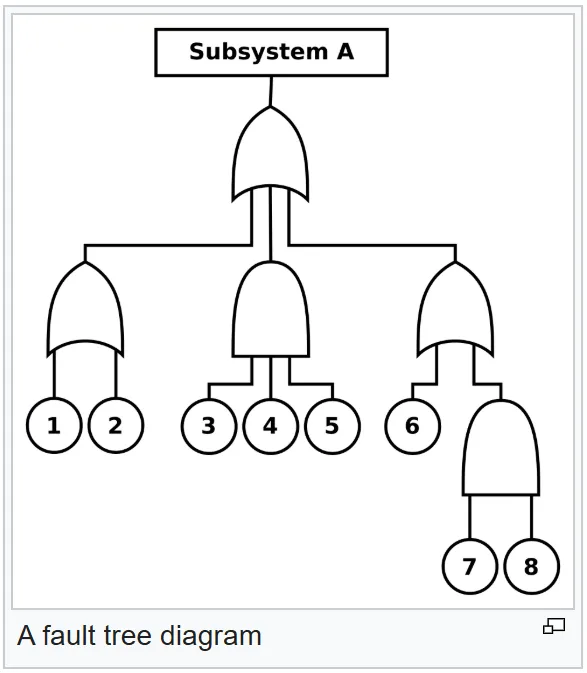 Reliability Engineering article on Wikipedia. In this case, the different components are "ORed" together, so Subsystem A only fails if all of the below components fail. Very reliable way to design!
Reliability Engineering article on Wikipedia. In this case, the different components are "ORed" together, so Subsystem A only fails if all of the below components fail. Very reliable way to design!
Failure Rate
Intrinsic failure rate is thus an important metric in design. In high-reliability electronics, the standard unit is Failures in Time (FIT), which is one failure per billion hours. Billion. With a B. That's 114,000 years. The inverse of failure rate is the more-legible Mean Time Between Failures (MTBF), which is usually measured in years. As a quick frame of reference to ground ourselves, 22,500 FIT corresponds to about 5 years between failures.
Not Poisson as in fish, it's just some guy

So what does Mean Time Between Failures...mean? Mean here is the formal statistical term for average. This doesn't really imply that if we have an MTBF of 5 years, we expect that the system will still be working after 5 years 50% of the time . It's more like a 37% chance that it'll still be working because we use failure rates as an input into an Exponential Distribution. Exactly how long your specific instance of the system will continue to work is definitionally random...as in it relies on a random variable, which in this case is [Time]. Real heads use what's called a Weibull distribution for modeling this, but we're going to go with a Poisson model because it only uses one variable that we've already defined, our failure rate.
Bottom Line: You can represent system failure rate as the interaction of component failure rates
Assumptions
So now, with all of this poorly summarized, let's create a quick list of assumptions for processes where reliability can be modeled as above:
- Assumption 1: Processes where events occur continuously and independently at a constant average rate
- Assumption 2: Processes which are memoryless
- Assumption 3: The system is in its "useful life period", so failures are meaningfully random. Lots of systems fail the first time they fire up (due to the grotesquely-named phenomenon of infant mortality), and once you reach the end of your expected service life the failure rate tends to skyrocket again
Gut Checks
Then, let's augment this set of mathematical assumptions with some better gut checks of what reliability feels like:
- If something is more reliable, its failure rate is lower (and the converse is also true)
- The more components in a system that must all be working at a given time, the less reliable it is and thus the higher its composite failure rate is
- If components in a system are redundant with one another, the more reliable it is and thus the lower its composite failure rate is
Case Study 1: The Overloaded Encounter Die
Now, you are probably seeing the immediate issue with applying reliability analysis to processes in tabletop RPGs. Despite Gary Gygax's best efforts, it is very hard to keep strict time records in games, let alone strict enough time records to actually use time as your random variable. However, there is one thing I want to use as a touchpoint for a very basic reliability system that people are familiar with: Necropraxis's original Overloading the Encounter Die. For the sake of simplifying this argument, let's say that we are assessing the reliability of our simple system: the humble torch. When it fails, it stops providing light to the party.
Assumption 1: Events occur continuously and independently at a constant average rate.
The smallest discrete unit of time during dungeon exploration in an old school game is the dungeon turn. Thus, making a check every dungeon turn is about as close to a continuous process as can be achieved with the time fidelity available to us. In this original post, torch expiration occurs as a 1-in-6 chance every turn. Each roll of the d6 is independent of the last roll, despite the gambler's fallacy. The odds do not change over time, so the average rate of 1-in-6 every ten minutes is constant: 1 failure per hour.
If you wanted a longer-lasting torch, it would need to be more reliable. A 1-in-8 chance of torch failure would stretch out the expected burn duration by about 25%.
Assumption 2: Events are memoryless.
As above, results of a d6 roll are independent of one another. This is also specifically why I am invoking this iteration of the mechanic rather than His Majesty the Worm's Meatgrinder - card draws without replacement are intentionally memory-ful, although once you account for deck shuffles it becomes much closer to a fully random process.
Assumption 3: Useful life period.
I wanted to invoke this original post because of a great comment from Brendan:
One might object: does this not lead to absurd results such as torches going out on the first turn or PCs needing to rest on the second turn? Well, yes, but you are an intelligent human, so ignore results that do not make sense. A result should be interpreted as not “X happens,” but rather as a prompt. A result can be deferred, but only so many times. The weight will naturally build up in the back of your mind as events proceed. As a guideline, ignore results above 3 for the first 6 or so turns.
Thus, GMs are given the permission to avoid premature failure conditions and allow the system to settle into its "useful life period".
As some commentary, I bring up torches as a reliability system in intentional contrast to some other iterations of torch implementation. I mentioned the memory of card draws inherent to HMTW's Meatgrinder system already. As for B/X, Dolmenwood, and other retroclones, torches are deterministic. They always last for exactly one hour, so they do not need to be examined through the lens of reliability. Finally, Shadowdark presents the opposite extreme; torches are deterministic in real time, which maps onto in-fiction time based on how much players can accomplish.
Case Study 2: Artifacts in the Cypher System
The Cypher system is built around consumable items called Cyphers. One-and-done. However, players may uncover or craft more powerful items called Artifacts, which act more like long-term buffs for player characters. Artifacts have an ability, and a chance that they will come due; when they come due, their powers dry up and require some action by the players to restore their abilities.
Also like cyphers, artifacts are simple for the GM to create. The only difference with artifacts is that you give them a come due roll, using any numbers on a d6, d10, d20, or d100. If you want the artifact to be used only a few times, give it a come due roll of 1 in 1d6, 1 or 2 in 1d10, or even 1 or 2 in 1d6. If you want the PCs to use it over and over, a come due roll of 1 in 1d100 more or less means that they can use it freely without worrying too much.
Old Gods of Appalachia, Page 287
I think this mechanic is slick! It gives GMs a few mechanical and narrative dials to fiddle with. However, it is not a good mechanic for modeling Reliability. The only box that it really ticks is the memoryless assumption. The check is not made continuously or regularly (although the probability of coming due is constant) and there is not a safeguard against premature failure. Still, I think the technique of modulating the die size in order to reflect something reliability-shaped (expected uses before failure) is a good takeaway.
With these ideas in mind, let's put a pin in reliability and tackle our second topic: mechanical fatigue.
Mechanical Fatigue
I took a few materials science courses in undergrad - it's an incredibly cool discipline for lab-based courses and an incredibly dry discipline to learn out of a book. Broadly, fatigue is the process of micro-imperfections in a material structure growing into cracks, which then become stress concentrators, which then leads to macro-sized failures. This happens due to cyclic loading, or rather the process of stresses being applied and relieved over time. As a concrete example, I used to work in an airplane repair hangar and we had to strictly track takeoffs and landings for each plane because those are the times that the planes are under the most stress.

Mechanical fatigue is random in an engineering sense because those micro-imperfections in the crystalline structure of materials are randomly distributed throughout their volume. The actual analysis of crack growth and fatigue is a little complicated to synthesize for a blog post about game design, but the gut feeling that you should take away (and probably already have) is that failure of a component due to fatigue is basically impossible at low numbers of "cycles" but the probability of failure increases (and changes shape) at high numbers of cycles.
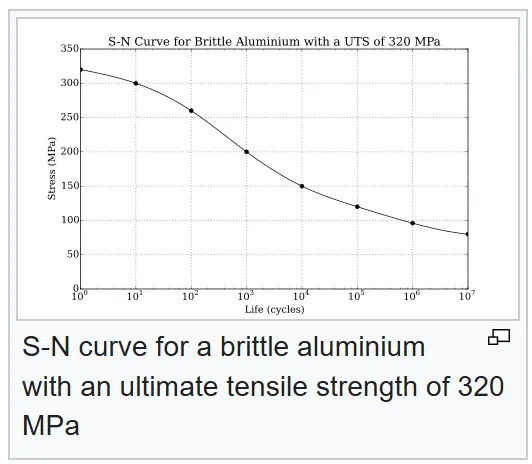
The above figure shows how less mean cyclic stress is required for a component to fail the more times that it is subjected to that stress. Alternately, you can laser focus at crack growth.
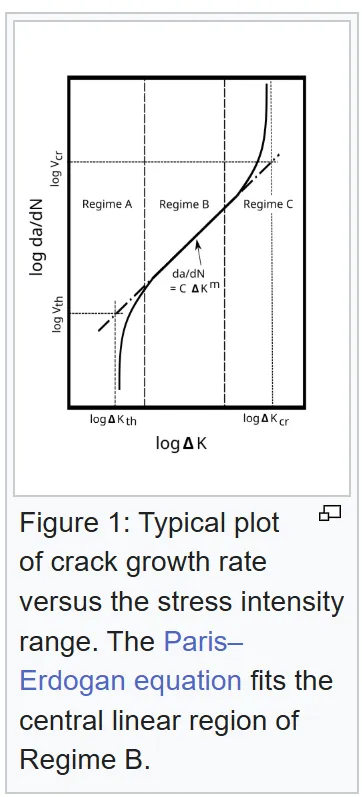
What this graph is showing is that the change in crack radius per cycle changes as the stress intensity changes.
Commentary
This is a weird phenomenon to try to model with a tabletop RPG, but I think we can actually get pretty meaningfully close with a Usage Die. The first place that I encountered Usage Dice is in Kobayashi's Black Sword Hack, a great adventure game published by The Merry Mushmen. The core principle of a usage dice is that the ability/item tied to it has an effect based on the current die size and die roll. However, whenever you roll a certain value (usually a 1 or 2), the usage die is stepped down in size, say from a d6 to a d4. Once you get to the smallest die size, a roll of a 1 or 2 consumes it, and that ability or item is exhausted or broken. The properties that emerge from this mechanic are:
- It is impossible to exhaust on the first use as long as you are not starting at the lowest die size
- The more you use the mechanic, the closer you get to exhausting it
If we revisit our case study of Artifacts in the Cypher system, they feel much more like a fatigue application than a reliability application (although coming due is still a one-and-done) because the check is performed each time the item is used - aka, it's checked each cycle.
At a more personal level, the panic system in Mothership is a slick way to model mental fatigue - you are more likely than not to fail most saves, and gradually your odds of panicking outweigh your odds of keeping your cool and thus doing in your character.
Putting it All Together
Reliability and fatigue are complicated engineering phenomena to analyze in real life, but they represent properties of materials and systems that feel real and have the capacity to feel dramatic. Like Nova says in her randomization post:
One common other use for randomisation where it isn’t a stand in, is where it is used to introduce dramatic tension. For this, the players need to know what the results might be and need to be hoping for a specific one.
The challenge is that in real life, reliability and fatigue are phenomena which would be best modeled by rolling a one billion sided die ten times per second of in-game time and waiting for it to come up as a 1. The risk of failure only comes into play over the course of years of in-game time. Beyond being impossible to play or conceptualize, that's not interesting. Your equipment failing at the wrong moment (or your equipment functioning against all odds) is exciting and dramatic. How can we represent that in a way that feels true-to-life by matching our gut instincts without being so true-to-life that it makes GURPS look like Lasers and Feelings?
Gut Feelings Revisited
- If something is more reliable, its failure rate is lower (and the converse is also true)
- The more components in a system that must all be working at a given time, the less reliable it is and thus the higher its failure rate is
- If components in a system are redundant with one another, the more reliable it is and thus the lower its failure rate is
- Synthesis: Modulating a die size to manipulate expected-uses-before-failure feels reliability-shaped
- The more you use something, and the more stress applied to it, the more likely it is to fail (cyclic loading)
As I've been writing this, I've been assembling a vision in my head of a mechanic that could pull these feelings together. My first-pass feeling is something partway between the Year Zero engine (like in the Alien RPG) and the G-Force mechanic in Erika Chappell's Flying Circus, or maybe just the panic system in Mothership. In the Year Zero engine, you assemble a pool of 6-sided dice for each skill check (they are funky dice but I think you can just use normal dice) and roll, looking for at least one 6 and hoping for as few 1s as possible. In Flying Circus, G-Force represents the strain on your airframe and applies a penalty to most of your in-air moves. These are both good bones for a reliability check!
Randomness at Play
Let's imagine a science fiction game where the players are crew on a ship. We'll call this hypothetical game something crazy like Internebula Bastionland. The ship is a creaky old rustbucket with a lot of capability and it has a number of key systems equal to the number of players. Something like Engines, Life Support, Weapons, and Navigation. Each system has a set of Functions and Reliability/Potency Dice - if a system's RPD are redundant, then they don't decrement unless all die show 1. If a system's RPD are serial, then a single 1 showing decrements all dice.
During transit, you make a periodic reliability check for all systems, which is a usage check against your reliability dice. For each reliability die that comes up 1, that die is decremented by a size and the overall ship Frame Stress is incremented by 1. The Frame Stress becomes the new difficulty check for takeoff, landing, or daring maneuvers in travel. If all Reliability/Potency Dice for a system are exhausted, then that system's Functions enter a critical state until the ship can be repaired.
This is a little bit goofy and baroque, but it scratches at some ways to marry our intuition about what reliability means with real-life ways of modeling the processes. That may be completely unappealing, but I think it's a fun thought experiment. You can also make this process GM-facing - it's not difficult to imagine a Mothership module set on a space station with multiple parallel systems that may all begin failing the longer that the players spend in it. I have played modules that involve timers and countdowns but gradual system failures that can be influenced by the players' actions seem juicy to me!
I do think reliability is a hard thing to introduce to a generic fantasy setting unless you recreate our idea of interlocking systems and say "but it's magic". The one place that it might be interesting and fitting is with concentration and magical rituals. I'm envisioning concentration as a dice pool that is rolled at every time step (maybe every dungeon turn, like an overloaded encounter die), and each die that comes up as a 1 is discarded from the pool. I like the idea of concentration as a random process with the characteristics of reliability or fatigue rather than a skill check/attribute save. Just something to noodle on!
Please let me know if this all makes sense - I didn't want to get overwhelming with this writeup and I hope I've made it digestible. Randomness is cool, and I think it's worthwhile to be intentional about where you introduce it in your game design!